seriych
 XVM Team
XVM Team
-
Posts
7,508 -
Joined
-
Last visited
-
Days Won
54
Everything posted by seriych
-
Они должны гармонично смотреться. А круги в ушах, лычки в маркерах вместе не смотрятся. Будем искать компромисс.
-
Увидел тут в конфиге silent_original лычки, которые мне очень понравились. Что думаете по поводу замены кругов на такие: Лично мне такие маркеры нравятся больше, чем с кругами. Но в ушах столбики не очень просматриваются, с кругами в ушах столбики лучше просматриваются.

-
@antey007, Отлично, успехов. Теперь уже настала моя очередь не понимать, о чем речь :-) Ты главное не делай допущений, которые противоречат реальным играм, типа того что распределение вероятности равномерно. Нам надо всё-таки оценить формулы, как они ведут себя в реальности, а не в какой-то там модели далекой от реальности. И функции я думаю надо растянуть под одинаковую дисперсию, ибо коэффициент растяжения для них до этого никак не обосновывался и выбирался наугад. Понятия не имею.
-
Почему? И на всякий случай, если вдруг до сих пор не понял: общая шкала гарантированно даст максимум только по одной из формул. Например dmitrylfk по двузнаному wn6 получит не 100, а баллов 80. Еще раз: двузначный макрос по каждой формуле свой будет: {{eff_2}}, {{wn6_2}}... и давать они будут разные баллы. И пересчитываться из eff и wn6 тоже по разным формулам.
-
@neLeax, Я же пишу "примерная", просто я функцию подбирал и примерный вид кинул. На самом деле все гораздо сложнее. По горизонтали должен быть отложен процент превышения, а не рейтинговый балл. Потом уже по проценту превышения корректируемой формулы надо определить формулу пересчета рейтинговых баллов в эту шкалу. С тем, какой процент превышения должен соответствовать каждому баллу, надо определиться заранее. Для этого абсолютно не надо ничего смотреть. И так понятно, что логарифмическая. Какой в этом смысл? Они только друг на друга смотрят, или только на себя? По-моему, как раз на всех игроков команд.
-
Мы количество знаков наоборот уменьшить хотим, а ты сотые :-) В теории да, можно, но в конфиге по умолчанию этого точно не будет. Это людям тоже будет непонятно, что 99% по сравнению с 98% - это бОльшая разница в скиле, чем 50% по сравнению с 60%. Не получится. Понимаешь, любое линейное соответствие очень быстро отклоняется от распределения по проценту превосходства, ибо там экспоненциальная зависимость. Только логарифмическая подходит.
-
Твои примеры не слишком упрощенные, они вообще не имеют связи с реальностью. Нормальные формулы делают комплексную оценку и сходу понять, какая формула лучше, нельзя. Иначе бы их столько не развелось. Мы считаем формулы изначально равноправными. А какую предпочтешь ты- это твое право.
-
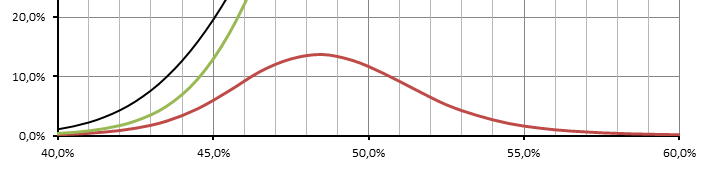
А что-то мне подсказывает, что распределение близко как раз к нормальному. Ибо если нарисовать зависимоть процента игроков от какого-то рейтинга (неважно, процент побед, рейтинг эффективности, или wn6, то это всегда будет колокол, похожий на нормальное распределение). Вот, например, распределение игроков по проценту побед: С рейтингами эффективности тоже самое. Понятное дело, что мы не знаем, как именно оценить силу команды в целом, по сумме всех игроков, но очевидно условная характеристика силы команды тоже распределена примерно также, как сила отдельных игроков(а сила все равно сильно коррелирует со всеми этими показателями). А если сила команд распределена нормально, то и вероятность победы будет нормально распределена(вроде бы). Так что есть мнение, что надо искать метод, по которому ты будешь оценивать формулы, дающие нормальное распределение прогнозов. По этим 180 боям я, кстати, рисовал- для каждой формулы колокола получались, правда кривоватые из-за малой выборки. Тебе в расчет шансов на победу надо утягивать среднее отклонение игроков от среднего рейтинга команды. Пусть есть две команды, с одинаковым средним скилом. Но среднее отклонение среднего скила в первой большое, во второй маленькое. То есть в первой, например, рейтинги 500, 1300, 2000, 100, 300, 1200... а во второй 1100, 1100, 1100... В среднем в обеих командах 1100, но вторая по идее лучше. Это можно учитывать, считая среднеквадратичное отклонение.
-
Примерная шкала, которая должна быть:
-
Я думал об этом примерно 2 секунды и сразу откинул эту мысль. Это будет не слишком интересно. 70% рейтинга будут занимать никому не интересные красные, в среднем диапазоне будет через каждые 10 баллов 1%, а в верхнем каждая прибавка процента превосходства- это огромный скачок в рейтинге: 70 - 1000 71 - 1010 72 - 1020 73 - 1030 74 - 1040 ...... 95 - 1400 96 - 1440 97 - 1490 98 - 1560 99 - 1670 То есть мы с отличной точностью делим дно, со средней средних игроков, с ужасной отличных игроков. А надо все наоборот. Чем больших игроков ты в рейтинге опережаешь, тем сложнее тебе подняться дальше. Ты по сути должен не подняться еыше превзойденных тобой 90%, а поднятся среди тех 10%, которые остались. Логарифмическая шкала для таких случаев используется.
-
Если показатель у игрока еще не определен, то цвет будет браться системный, то есть лычка вместо белой/серой(неопределенной) будет рисоваться зеленой/красной для союзников/врагов. Надо "неопределенный" цвет определить, типа такого: "format": "<font color="#FCFCFC"><font color='{{c:e}}'>/</font></font>"
-
Если ты считаешь какую-то формулу абсолютно неадекватной, то ты не будешь ее использовать ни в таком виде, ни в первоначальном и тебе вообще должно быть побоку, подгоняется она под единый стандарт, остается в изначальном виде или ее вообще не существует. Интересуют лишь адекватные формулы. Соответственно грош цена изначальной формуле, а не шкале.
-
Да, что-то я не подумал, что лучше в старом формате отправить. Ну да ладно, это мелочи жизни. Да, я выше писал, что я растягиваю/сжимаю все формулы под одно среднеквадратичное отклонение. Это оно и есть. Не вижу ошибок в математической модели, которую я тебе по скайпу изложил, соответственно не вижу оснований менять функцию оценки прогнозов. Единственное, где можно применить интегральную функцию- это для сравнения оценок при разной пологости. А то чем положе графики оценки, тем выше сумма баллов. Есть предположение, что если поделить оценку на площадь под черным графиком(как раз интегральная функция, точнее сумма трех интегральных), то получим значения, которые можно сравнивать между собой при разной пологости. Хотя не уверен. Я не знаю этого метода. Если ты в нем уверен, то нет оснований не доверять результату, тем более что он такой же. Вот соберем базу побольше, проверим на нескольких тысячах боев, и если будут расхождения, будем думать. Почему? Если это так: То получается распределение вероятности победы тоже равномерно от 0 до 100%. А это неверно. Чаще встречаются команды с примерно одинаковым средним скиллом, чем с очень сильно отличающимся. Соответственно реальная вероятность победы чаще ближе к 50%, чем к 0 или 100. То есть реальное распределение вероятности исхода неравномерно.
-
О, Боги, в которых я не верю, спасибо вам, что вы меня услышали и хоть кто-то начинает понимать, что мы делаем вещи полезные, а не наоборот что-то портящие! Я в последние дни чуть ли не головой об стол бился, пытаясь понять, почему все мои объяснения напрасны. Наконец, с -дцатой попытки получилось. Пойду прогуляюсь, озаряя прохожих счастливой улыбкой :-) Суть я высказывал кучу раз кучей разных способов, но всё было без толку.
-
Мне кажется это надуманная проблема. Что-то сейчас не особо слышно в чатах:- Ой, у тебя процент побед убогий. - На себя посмотри, эффективность ниже плинтуса. Если так думает государственная власть, то получается тоталитарное государство, население которого в большинстве своем против текущего положения вещей. Устроим всеобщее голосование за одну формулу- демократия, большинство довольно, меньшинство не имеет способа что-то изменить. А предоставление максимальных свобод, как мы хотим, - это либеральное государство, делаем, как нам кажется лучшим для большинства, но оставляем любые возможные варианты для всех желающих. Все довольны результатами, недовольны только тем, что остальные могут поступать как им заблагорассудится, наперекор большинству. Как-то так :-)
-
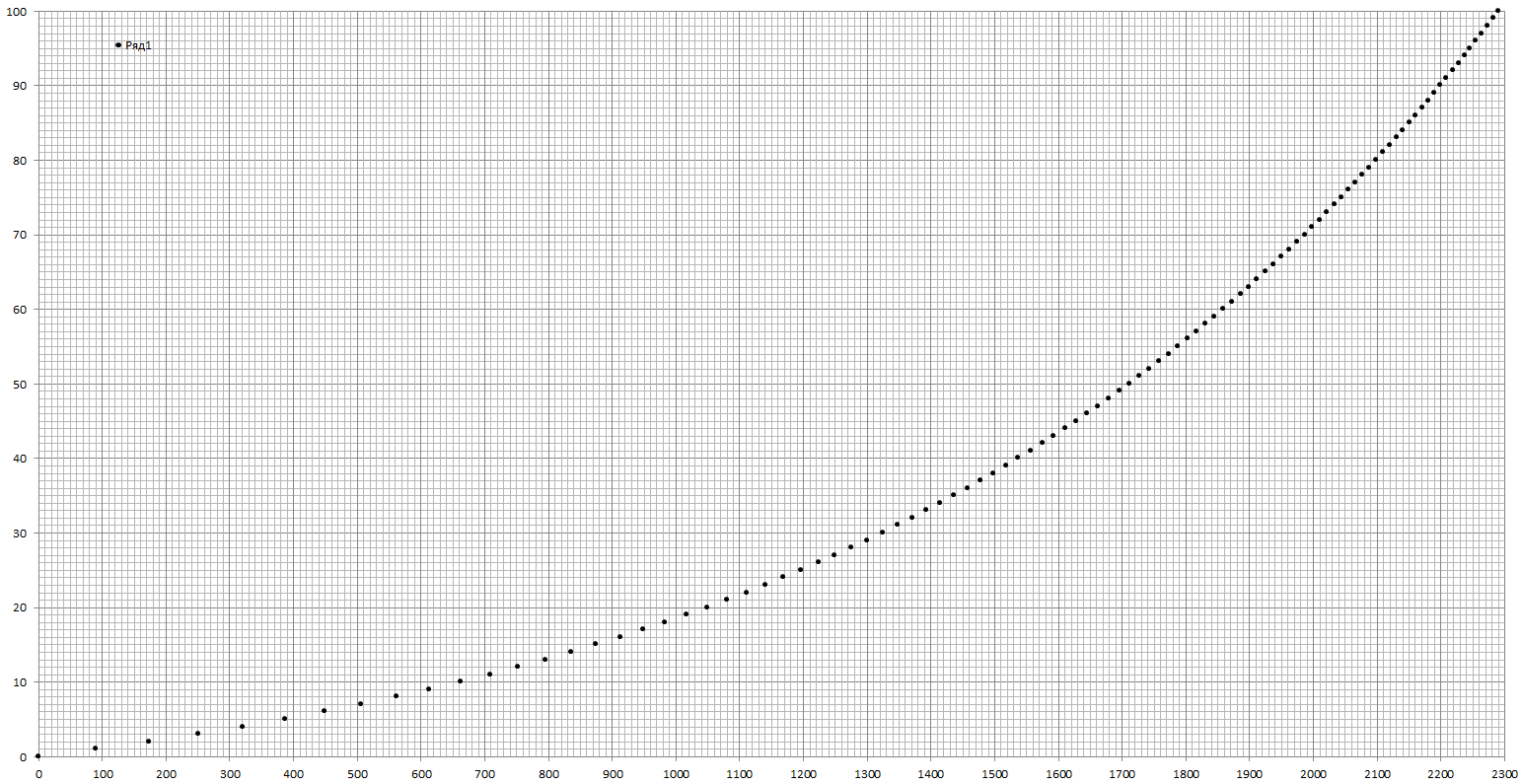
Тогда мне непонятно распределение по количеству боев. Оно такое, как будто игра совсем новая и поэтому чем больше боев, тем меньше народу успело отыграть большее количество боев. Но WoT вроде как совсем не новая и есть определенное количество постоянно играющих игроков, которое вроде как должно быть значительно больше новоприбывших за 45 дней. Мне кажется, что это должна быть не функция нормального распределения. Нам по идее надо следующее. Пусть игроков в диапазоне шкалы 0-10 N штук, тогда в диапазоне 10-20 их должно быть N/2, в диапазоне 20-30 N/4, в диапазоне 30-40 N/8 и т.д. То есть функция получается логарифмической, только сдвинутой на единичку, чтобы через ноль проходить. Ну и N/2 условный коэффициент. Там надо будет подобрать самый удачный.
-
Все-таки ты не понимаешь. Именно из-за таких мыслей люди и отвергают нашу идею, считая, что мы формулы друг к другу подгоняем. Мы предлагаем не формулу, а шкалу, по которой будут откладываться все формулы. Для каждого конкретного игрока число по приведенной шкале по разным формулам будет разным(хотя иногда иногда и одинаковым). Вот пусть есть игрок, который имеет большой балл по среднему захвату. Скажем по приведенной eff игрока оценит на 40, а по приведенной wn6 на 43(ибо захват не учитывается). И это будет однозначно показывать, что по wn6 он имеет рейтинг выше, чем у большего процента игроков(скажем 65%), по сравнению с процентом игроков выше которых он имеет рейтинг по eff(скажем 60%). Ну ты же не можешь залезть на все сайты и добавить туда что хочешь. В XVM будет эта шкала, люди будут ей пользоваться(особенно если по умолчанию включим), сайты со временем добавят. На официальном можно сделать сравнение. Мне тоже. А что делать с этим: http://www.koreanrandom.com/forum/topic/2625-wn6-vs-eff-in-default-config-wn6-или-eff-в-конфиге-по-умолчанию/?p=34780
-
Ну хоть один понял. Кстати, wn6''' как раз это и делает, только подгоняется не к двузначной шкале, а к шкале, по которой уже сейчас привычно считается eff. И если wn6''' показывает то же значение, что и eff, то это значит, что wn6 (без штрихов!!!) оценила тебя так же, как eff (не по числу, а по проценту игроков, лучши которых ты по ее мнению играешь). Правда если сейчас eff изменили, то вообще привычная шкала исчезла (если они новую к старой таким же образом не подгоняли, что сомнительно, учитывая, что в формуле этим и не пахнет)
-
Разница в том, что мы сможем сделать для всех формул не 36 вместо 1000, а 36 вместо превосходства над скажем 60% игроков. По одной формуле в 36 будет переходить 1000, по другой 1150, по третьей 900, по десятой -75000... Но мы будем всегда знать: если две разных формулы написали по 36, то это значит что они обе оценивают игрока одинаково хорошо. А если одна написала 37, а другая 36, то значит первая оценивает тебя лучше, чем вторая. Вот поэтому я и предложил, раз авторы формул такие непробиваемые и не понимают, заем нужна нормализация под единый стандарт, то сделаем свой стандарт. Хотите- юзайте четырехзначные числа, из которых никогда непонятно, кого лучше, а кого хуже оценили, если там разница не в пару сотен(имеется в виду сравнение оценок по разным формулам). А хотите используйте стандартизированную шкалу процента превосходства, по которой если у тебя показывает больше, значит больше и есть.
-
Тебе правда привычно, что 1000 по eff - это лучше, чем 55% игроков, 1000 по wn6 - это лучше, чем 70% игроков, а 1000 по новой eff вообще неизвестно лучше скольки? И так для любого другого значения.
-
Если этот: 1150 --> ~52, то тупо домножением первого на 0,045. Взял из того, что людей с рейтингом выше, чем 99,5/0,045=2211 примерно 30 человек(по wn6) и им всем можно написать XX - сто. Естественно, 0,045 это не строгое число, просто примерный вариант. Если этот: 1150 --> ~40, то от балды. Точную функцию ужатия дна еще подобрать надо. Но смысл я примерный отобразил, +1 в двузначном рейтинге для днищ обозначает много(+100 старых баллов), а для нормальных игроков мало(+10 в старых баллах). Ну и плавно переходим от больших шагов к малым.
-
Нет.В первом приближении получится 1150 --> ~52. Число градаций снизится примерно в два раза. То есть если раньше ты мог отличить между собой игроков с разницей в 10 баллов, то с двузначной шкалой будет ~20 исходных баллов: 1150 --> ~52 1160 --> ~52 1170 --> ~53 1180 --> ~53 1190 --> ~54 1200 --> ~54 Это если тупо домножать на 0,045. Но предлагается сделать еще лучше: для нижнего диапазона число градаций снизить, а вверху останется примерно таким же. То есть примерно так: 0 --> 0 100 --> 1 150 --> 2 200 --> 3 250 --> 4 300 --> 5 340 --> 6 380 --> 7 ... 1150 --> ~40 1160 --> ~41 1170 --> ~42 1180 --> ~43 1190 --> ~44 1200 --> ~45 То есть жертвовать точностью снизу(кому она нужна?, тем более, что она там зачем-то растянута изначально) и сделать шкалу сверху такой же или даже превосходящей по точности.
-
Я думал рейтинги считаются на стороне клиента. Может сделаем так: добавляем все новые формулы, как того хотят разработчики, но делаем дополнительно для каждой формулы двузначную шкалу в соответствии с выбранными процентами превышения. И все довольны. Что в конфиг по умолчанию ставить- это уже другой вопрос.
-
Мне больше интересно, как будут сравнивать значения этих рейтингов те, кто не понимает, зачем я подгонял по реперным точкам. А таких походу большинство(и на американском форуме тоже). И посмотри, что я выше написал. В смысле в последней тестовой версии {{eff}} заменено на эту формулу?
-
Это не последнее решение, это одно из решений. @sirmax, Слушай, а ты можешь сделать выборку по игрокам, сыгравшим хотя бы один бой за последние скажем пару месяцев или любой другой срок? Зачем это надо. Ты видел графики выше, показывающие распределение игроков от количества боев. Меня интересует не синий график а красный. Я полагал, что это будет "колокол" типа нормального распределения(не интегрального, а обычного), что на первый взгляд вроде как логично: игроки быстро набирают бои, основная часть игроков скапливается в районе нескольких тысяч боев, а выше какого-то числа опять идет спад- самые заядлые геймеры остаются. Отсюда и предположение, что резать по 200+ или 1000+ по сути без разницы, ибо основная масса игроков все равно выше. Однако никакого колокола нет и в помине, зависимость такая: чем меньше боев, тем больше игроков. И тут я понял, из-за чего это происходит. В базе огромный процент игроков, которые уже давно не играют. Человек начинает играть, потом надоедает и он прекращает. Но в базе он остается. Кто-то вообще пробует и сразу забивает на игру. Кто-от пробует несколько боев, кто-то несколько десятков. И так изо дня в день, из месяца в месяц. Эти игроки копятся и копятся, остаются в базе и остаются, а среди новых тоже часть кто тоже забил на игру. Вот мы и получаем, что куча игроков, участвующих в нашей статистике, никак не влияют на игровые действия, на взаимоотношение сил. Но при этом они есть в базе и они учитываются при подсчете ВСЕХ средних показателей реально играющих игроков. Это весьма неприятный момент, однако. Соответственно, они учитываются и при моих расчетах. Если порезать по 2000+(или другому подобному числу), то влияние, конечно, сильно уменьшится, но всё же лучше было бы иметь базу по тому, как распределены реально играющие игроки. И для всех остальных средних показателей в статистике XVM это нужно.